01 · GPUs idle at sub-30% while the data loader does all the work
The Challenge
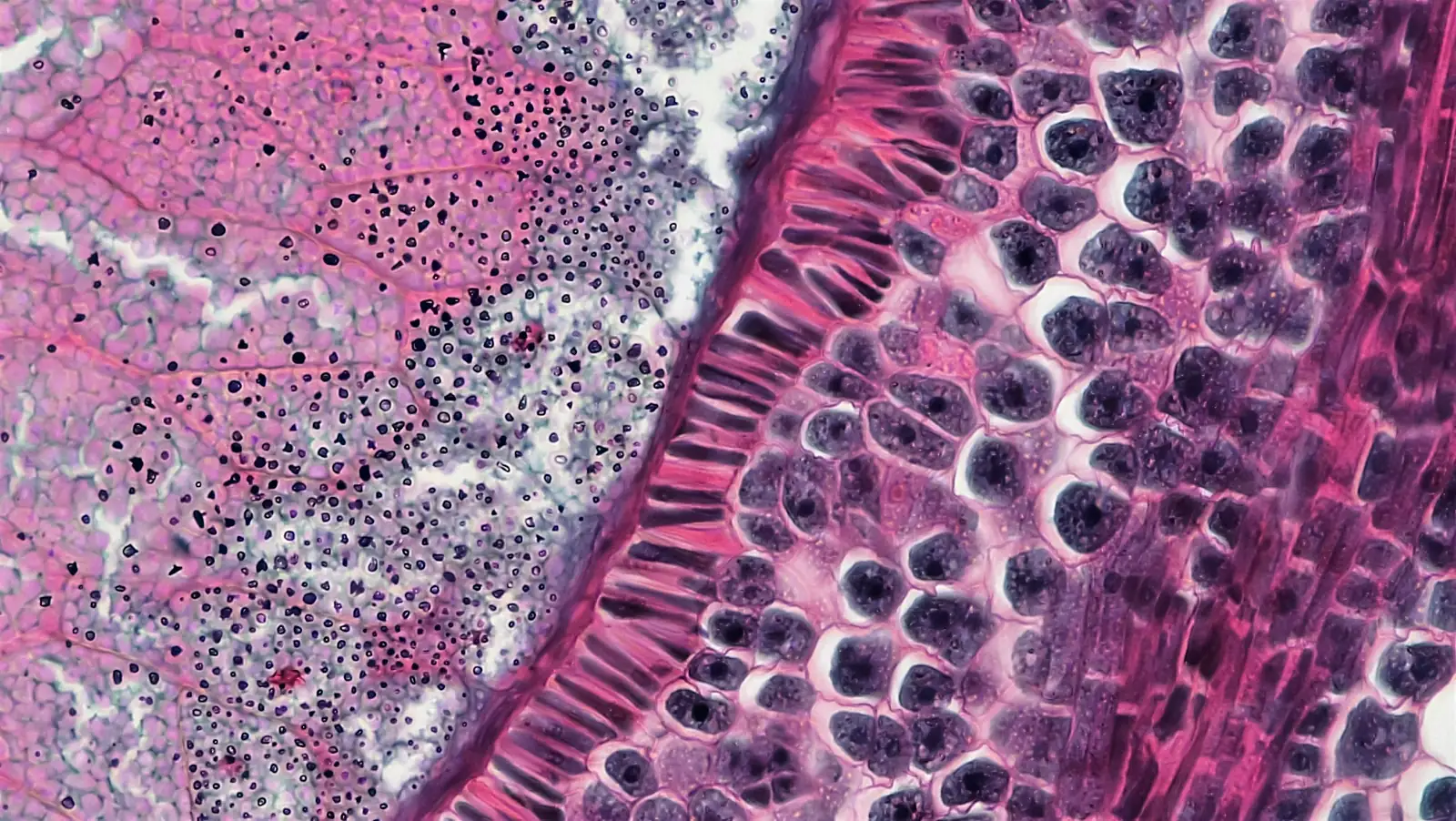
The customer is an early-stage medical imaging startup. The model they needed to ship was a single-head Gleason grading + segmentation network on full-resolution prostate biopsy WSI - gland-level Gleason pattern classification (3, 4, 5, plus benign tissue and high-grade PIN) and pixel-level tumor segmentation of the same regions, so a downstream pathologist gets both a primary/secondary pattern call and an annotated mask they can review in the digital pathology viewer. The clinical promise is real: prostate core-needle biopsies are high-volume, Gleason scoring drives the treatment decision, and inter-observer variability between pathologists on patterns 3 vs. 4 is well documented - a second-reader AI that surfaces equivocal regions with a localized mask has a credible path to clinical adoption. The problem was that the team's training loop wasn't keeping up with their own labeling throughput.
A single annotated WSI in their cohort is a pyramidal H&E slide at 40× scan magnification - roughly 100,000×100,000 pixels at the base level, 5–20 GB on disk per slide, with multiple cores per case and stain/scanner variation across the cohort. Their training pipeline pulled tiles through OpenSlide on every epoch, decoded JPEG-compressed tiles on the CPU, ran tile augmentations (random crops, rotations, color jitter, elastic deformations, stain perturbations) on the CPU, and then pushed the result to the GPU. The result on their 8×A100 box was textbook starvation: GPU utilization hovering around 25%, single-epoch wallclock around 9 hours on the curated training set, and an iteration loop where a single hyperparameter sweep took most of a week.
Two non-negotiables shaped the rebuild. PHI couldn't leave the hospital VLAN - WSI ingest, training data, and model artifacts all had to live inside the customer-controlled environment, with no cloud step in the loop. And the rebuild had to land on the same 8×A100 box the customer already owned; raising more capital to buy more GPUs because the data loader was inefficient wasn't a plan their seed round could afford.