Can an AI Learn to Bluff Only by Playing Against Itself?
Reinforcement learning experiment on the imperfect-information game of Liar's Dice.
Karol Kłusek
May 12, 2026 · 8 min read

This article is a small experiment in that direction. We train an agent to play Liar’s Dice with reinforcement learning, watch what happens during self-play, and check whether bluff-like behavior appears.
Liar’s Dice Game

The short version: you and your opponent roll dice, but keep them hidden. Then you take turns making claims about how many dice of a given face exist across both players’ hands. At any point, a player can call Liar! and challenge the previous claim.
The best way to understand the game is to see it in action!
You can either watch the Pirates of the Caribbean scene here:
or play against AI here: dudo.ai
Similarities to Poker
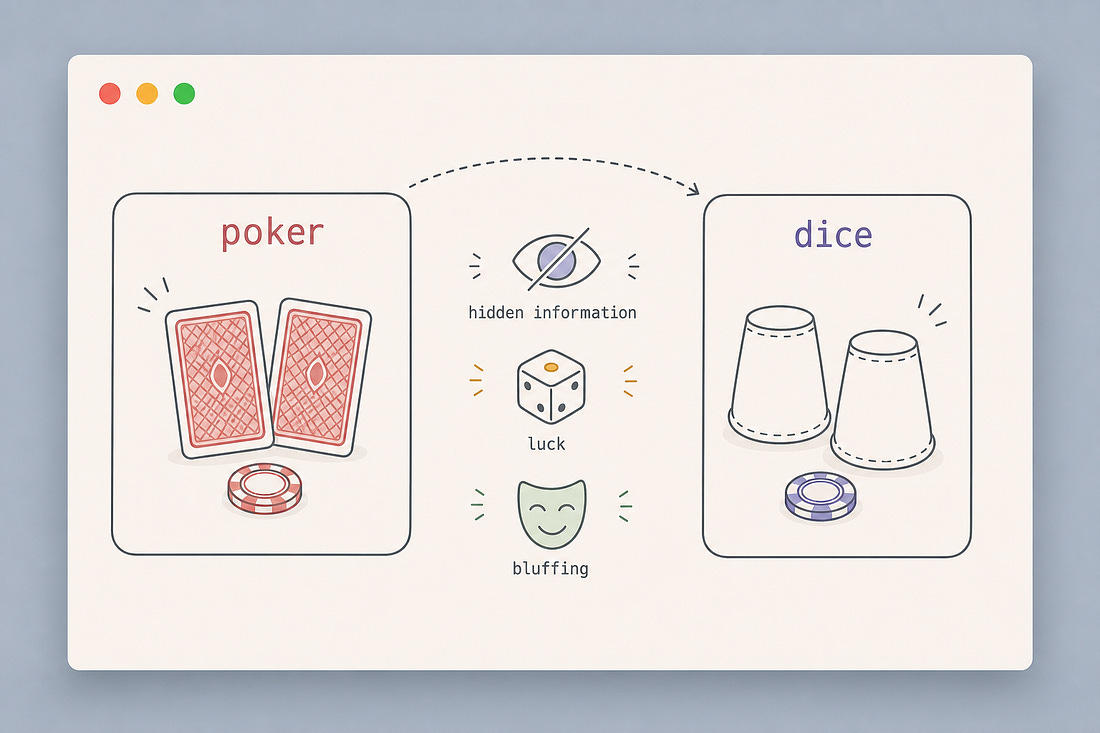
Liar’s Dice is like a simpler version of poker. It has:
- private and public information,
- luck and bluffing,
- gradual information reveal through betting,
- exploitable repetitive strategies,
- pressure to balance safe play with risky bluffs.
You are not always lucky with your roll, but you can still win by bluffing. That is what makes the game interesting for reinforcement learning: the agent cannot simply “calculate the best move” from the full state, because part of the state is hidden.
Jaxpot
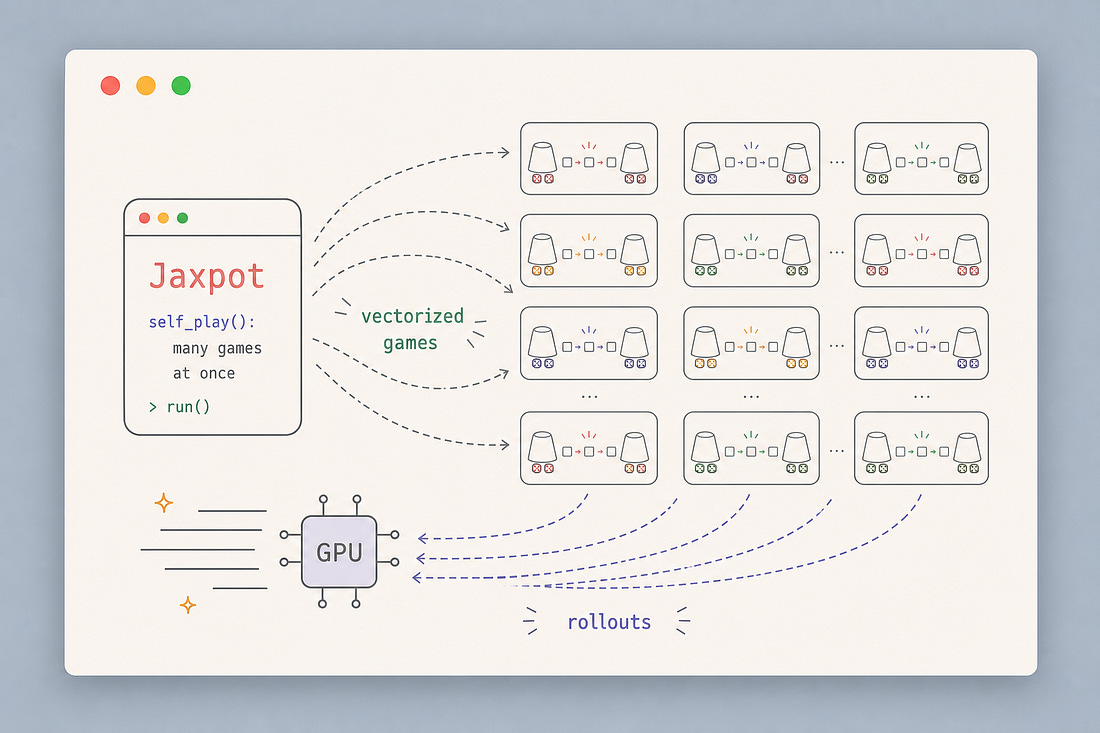
While working on a poker bot for our client, we developed Jaxpot: a framework for running reinforcement learning experiments in a reproducible way while making full use of accelerators.
Jaxpot does not only use the GPU to train the neural network. It also uses it to run thousands of parallel games, which makes self-play training much faster.
If you want more context, here is our previous Substack article:
Related: Jaxpot: Train self-play RL agents FAST by parallelizing environments on GPU
We got hired to build a poker bot.
Experiment Setup
In this experiment, we train an agent on a two-player version of Liar’s Dice:
- 2 players,
- 5 dice with 6 sides per player,
- the highest face,
6, is wild, - reward is
+1for the winner and-1for the loser.
The question is: if the agent only improves by playing games, can it discover bluffing behavior on its own?
Model Inputs
Before an RL agent can play Liar’s Dice, we have to turn game into it’s numerical representation.
A human can look at the table and think:
No way he’s got 4 x 6s! i should call LIAR!
A neural network learns to guess with vectors as input and logits as output.
The environment defines three things:
- what the agent sees,
- what actions it can output,
- which of those actions are legal in the current state.
In Jaxpot’s Liar’s Dice environment, this interface is visible directly in training code:
1@dataclass2class State(core.State):3 current_player: Array = jnp.int32(0)45 # Default for 5 dice per player6 observation: Array = jnp.zeros(90, dtype=jnp.float32)7 legal_action_mask: Array = jnp.ones(61, dtype=jnp.bool_)89 rewards: Array = jnp.float32([0.0, 0.0])10 terminated: Array = jnp.bool_(False)The important numbers are 90 and 61.
90 is the size of the observation. 61 is the number of possible actions.
Action Space
In our setup, there are 10 dice in total: 5 dice per player. A bid is a pair:
(quantity, face)The quantity can be from 1 to 10, and the face can be from 1 to 6. The player can also call Liar!, so the full action space has:
60 bids + 1 liar call = 61 actionsIn the game logic, those actions are represented as integer IDs:
1DICE_SIDES = 6234def _num_actions(num_dice_per_player: int) -> int:5 total_dice = 2 * num_dice_per_player6 return total_dice * DICE_SIDES + 1789def _liar_action(num_dice_per_player: int) -> int:10 total_dice = 2 * num_dice_per_player11 return total_dice * DICE_SIDES121314def _bid_quantity(action_id):15 return action_id // DICE_SIDES + 1161718def _bid_face(action_id):19 return action_id % DICE_SIDES + 1The model outputs 61 logits, one for each possible action. Always choosing the highest logit would make the agent predictable. Instead, we sample from the policy, so the same position can sometimes produce a safe bid and sometimes a bluff.
Legal Moves
Not all actions are legal in every state.
If the current bid is already “three 4s”, the agent cannot bid something lower. It can only make a higher bid or call Liar!.
That rule is handled by the action mask:
1def _legal_action_mask(state, num_dice_per_player):2 n_actions = _num_actions(num_dice_per_player)3 liar_id = _liar_action(num_dice_per_player)4 action_ids = jnp.arange(n_actions)56 # Bids must strictly increase7 bid_mask = (action_ids < liar_id) & (action_ids > state.current_bid)89 # "Liar!" is only legal after at least one bid exists10 liar_mask = (action_ids == liar_id) & (state.current_bid >= 0)1112 return bid_mask | liar_maskObservation Space
1agent observation2├── private: own dice only3└── public: current bidding stateThe agent should see its own dice and the public bidding state. It should not see the opponent’s dice.
The private part is encoded as one-hot vectors. With 5 dice and 6 possible faces, that gives:
5 dice × 6 faces = 30 valuesThe public bidding state is represented as a 60-dimensional vector: one slot for every possible bid.
1my_dice = jax.lax.select(color == 0, state.dice[0], state.dice[1])2dice_onehot = jax.nn.one_hot(my_dice - 1, DICE_SIDES).reshape(-1)34bid_ids = jnp.arange(num_bids)5bid_history = (bid_ids <= state.current_bid).astype(jnp.float32)6bid_history = jnp.where(state.current_bid >= 0, bid_history, 0.0)78observation = jnp.concatenate([9 dice_onehot, # 30 values: private dice10 bid_history, # 60 values: public bid state11])So the final observation has:
1observation.shape == (90,) # 30 private dice values + 60 public bid values2policy_logits.shape == (61,)3legal_action_mask.shape == (61,)Training Loop
Once the game has a fixed interface, the training loop becomes simple:
play games -> collect experience -> update policy -> repeatDepending on available VRAM, we want to run as many games in parallel on the GPU as possible. The neural net is trained on the GPU, but the games themselves could also be simulated there. This is how we’re making this experiment fast enough to run even on Colab free GPU!
Just look how fast the Jaxpot implementation is compared with PyTorch or NumPy:
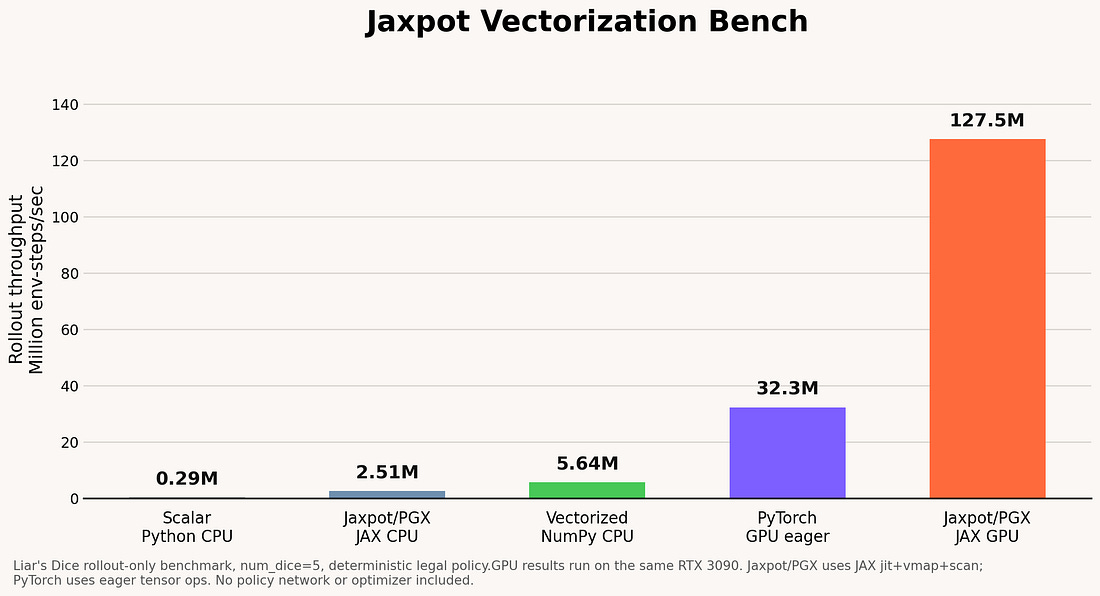
For this run we used PPO, a policy-gradient reinforcement learning algorithm. The policy/value model was a small MLP with hidden layers [512, 256, 128].
At the beginning, it is useful to train against a random opponent. Random player is not strong, but it teaches the model the basic mechanics of the game. The agent learns how legal moves work, how rewards are assigned, and how to exploit obvious mistakes.
In our run, the first 200 iterations included this random-opponent warmup signal. After that, training continued mostly through self-play and league-style opponent sampling.
Pure self-play has a classic problem: the model can become too specialized against the strategy that is currently dominant. It may learn to beat itself, while forgetting how to beat older, simpler, or just different styles of play.
To make training stable, Jaxpot lets us mix different opponents into the training process:
The agent can collect experience from several matchups:
1current agent2 |3 |-- plays against: itself4 |-- random opponent5 |-- heuristic baseline6 |-- league snapshots7 `-- archive opponents8 |9 v10collected trajectories11 |12 v13PPO update14 |15 v16new current agentFor initial rollouts, we used this quantities:
1random_warmup_iters: 2002selfplay_num_envs: 81923random_num_envs: 40964league_num_envs: 8192Training Results
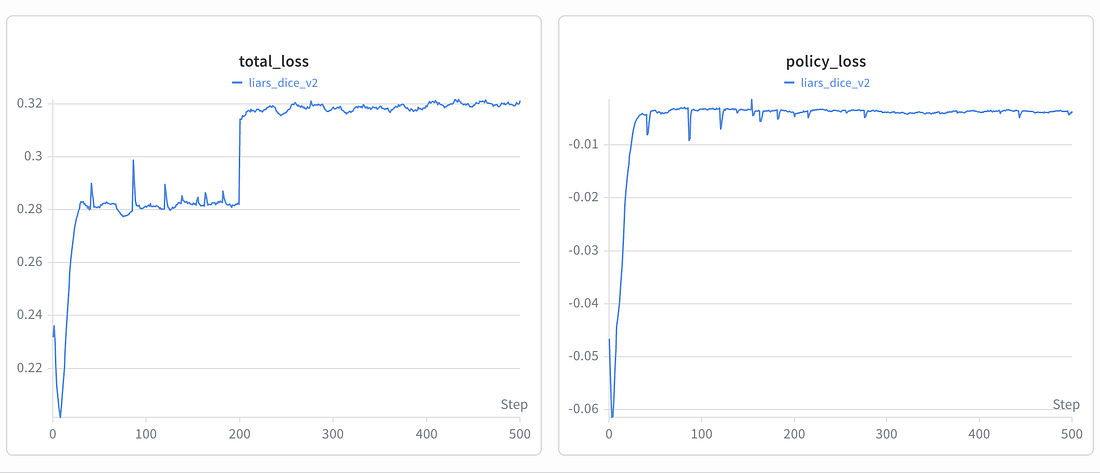
First we checked loss but it’s not really important. That may sound strange if you come from regular supervised learning. In a typical ML project, if the loss goes down, we know it’s going in right direction.
In self-play, the dataset is not fixed. The agent is constantly generating new data by playing games against changing opponents. When the policy changes, the games it produces also change. So the loss curve is not measuring progress on a stable dataset. It is measuring how well the current update fits the latest batch of games.
That is why the most important question is:
Does the agent actually win more games?
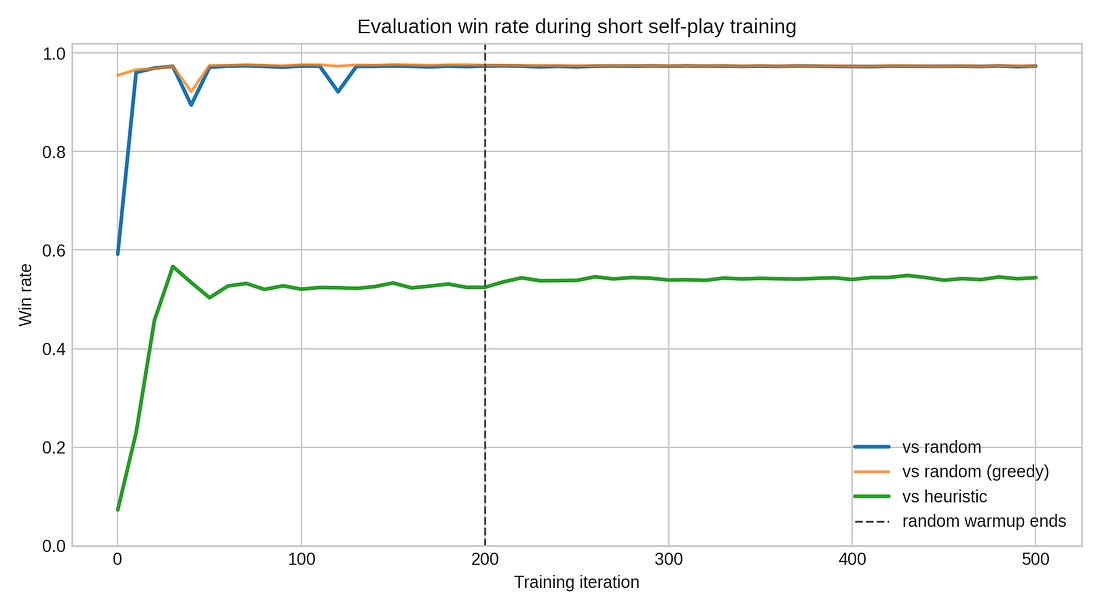
Evaluation win rate over training
Against a random player, the win rate jumps almost immediately and then stays around 97%. This means the training is stable.
But random play becomes too easy very fast. The more useful curve is the heuristic baseline.
The heuristic baseline is the better test. It is still simple, but it knows the rough shape of the game: count your own dice, estimate whether a bid is plausible, and call Liar! when the previous claim looks too optimistic. Against that opponent, the agent climbs above 50% and then mostly plateaus.
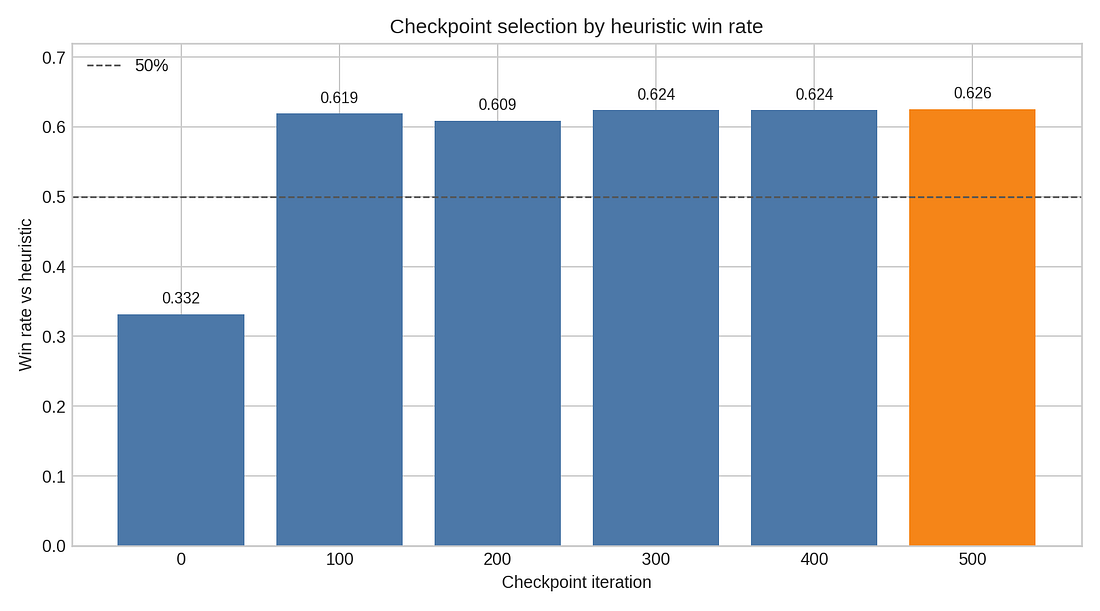
Checkpoint selection by heuristic win rate
So instead of trusting the final loss, we saved checkpoints every 100 iterations and evaluated them as players.
That gives a more honest picture. The first checkpoint is already strong against random play, but weak against the heuristic. After 100 iterations, the model has made the big jump. Later checkpoints are all in roughly the same band. In this W&B run, checkpoint 500 was the best in the direct sweep, but not by a dramatic margin.
That is a useful RL lesson: latest is not automatically best. Save checkpoints and make them play.
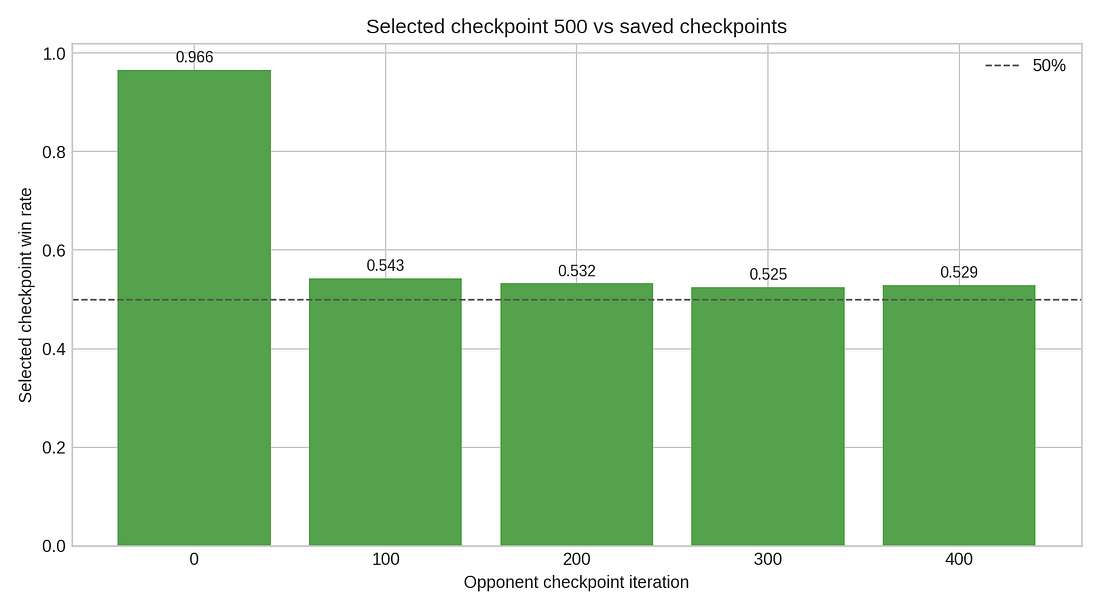
Selected checkpoint vs earlier checkpoints
The selected checkpoint easily beats the initial policy. Against nearby checkpoints, the games are much closer. That suggests the model learned the core game quickly, then just applied small changes to a local optimum.
For Liar’s Dice, that makes sense. There is no single correct move. A good player must sometimes bid honestly, sometimes stretch the truth, sometimes call Liar!, and sometimes let a suspicious bid pass.
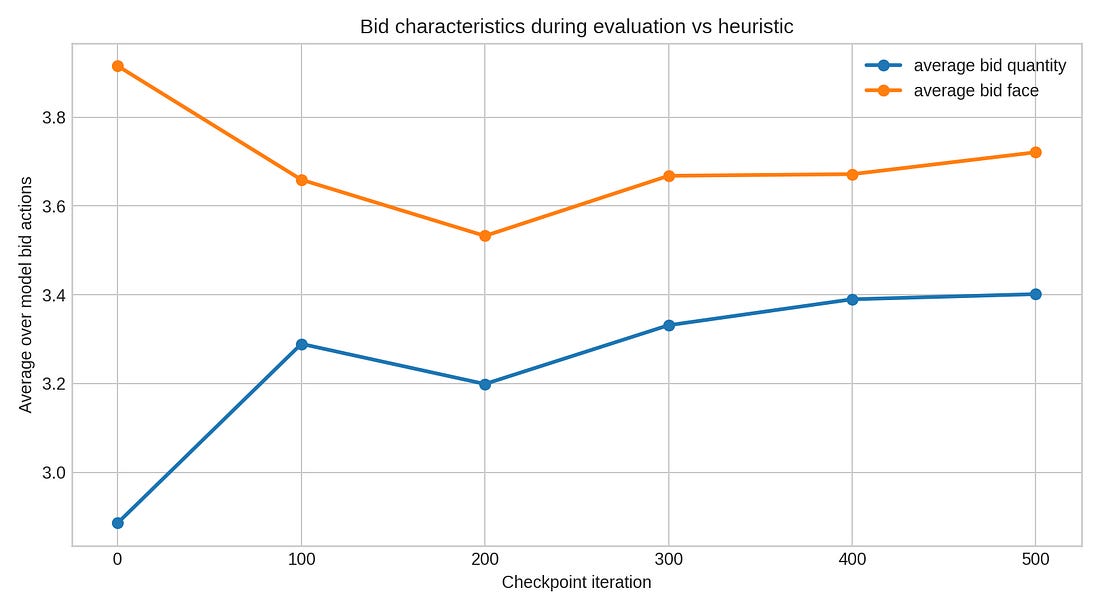
Bid characteristics
The bid-characteristics plot gives a small hint that the policy changed style. The model starts making stronger claims. It is learning to apply bid pressure earlier so the opponent have less chances for safe plays. In other terms: the model learn to bluff to win!
You can train this exact experiment using Jaxpot on google Colab GPU. Here’s our previous article with quick start guide:
Related: Jaxpot: Train self-play RL agents FAST by parallelizing environments on GPU
We got hired to build a poker bot.

Written by
Karol Kłusek
ML Engineer @ bards.ai
Working on reinforcement learning and self-play systems. Author of Jaxpot.
Like this article?
Get practical insights on AI, product, and growth sent to your inbox.


