Fine-tuning best 7b LLM model
The Jaskier 7b model achieved first place ranking for models up to 7 billion tokens on the HuggingFaceH4/open_llm_leaderboard.
Karol Samorański
Feb 25, 2024 · 10 min read

Our bardsai/jaskier-7b-dpo-v5.6 model is ranked number one for models up to 7 billion tokens according to the popular HuggingFaceH4/open_llm_leaderboard.
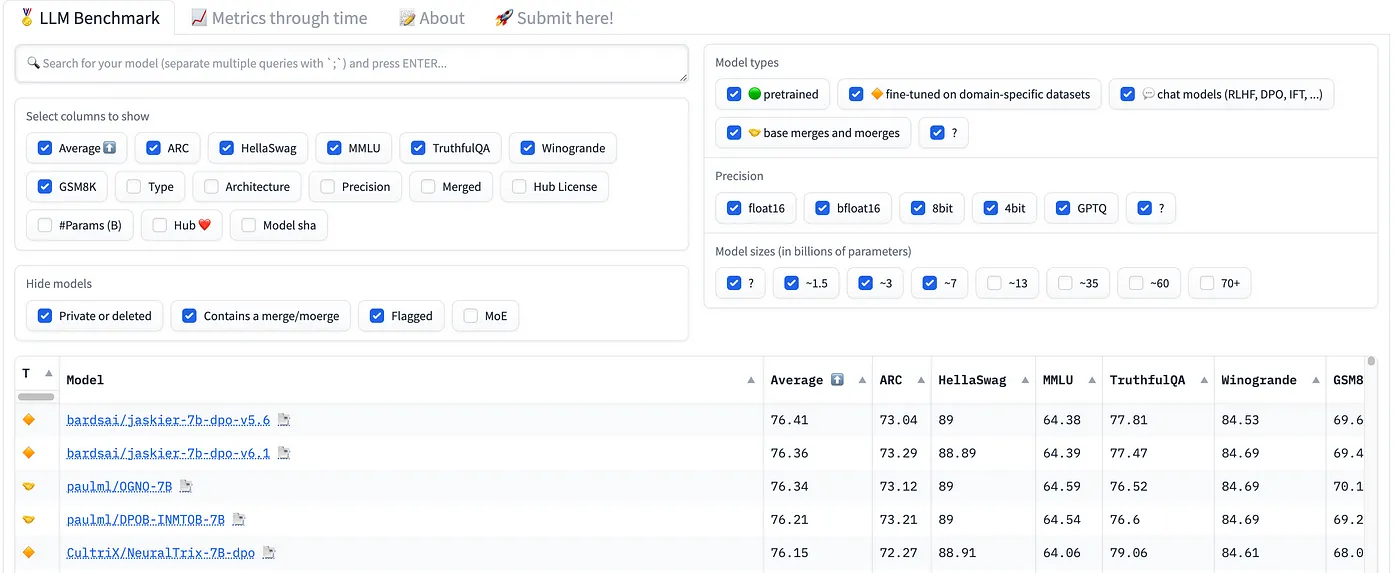
I will share with you the path that has allowed me to achieve this goal. Below are the considerations as well as the technical problems I encountered while working on this model. To utilise this text effectively, it will be necessary to understand fine tuning methods, the construction of data sets for it and the metrics considered when evaluating the model in the leaderboard.
DPO
During training, the objective is to ensure that the model produces higher probabilities for preferred answers than the reference model, while generating lower probabilities for rejected responses. This involves penalising the LLM for incorrect answers and rewarding it for correct ones. To achieve this, preference datasets are used.
These datasets do not have a hierarchical structure and may vary in terms of naming conventions or number of available features. It is necessary for data sets to include a prompt and two possible responses (chosen and rejected text). These responses are selected as correct or incorrect by a judge, who can be a person or another language model. An example of this type of dataset is argilla/distilabel-math-preference-dpo, which has the following structure:
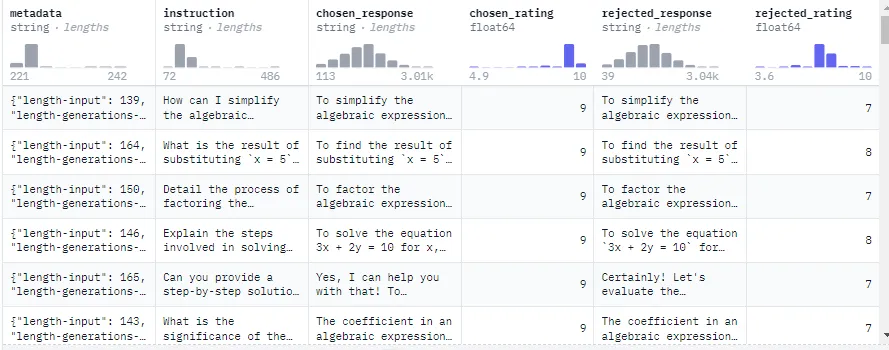
It can be seen that in addition to the necessary features mentioned, it has columns such as the evaluation of selected and rejected text, these can help to filter the training data.
Phase I
My first shot was the idea of simply training the best model on a relatively sensible dataset.
I selected a model from the top-ranking in the HuggingFaceH4/open_llm_leaderboard, in the category of models with up to 7 billion tokens and dataset lmsys/chatbot_arena_conversations. The Google Colab notebook prepared by Maxime Labonne was a great help for fine-tuning.
The code below implements reformatting of the dataset to make it compatible with the Mistral model's conversation template.
1final_df = pd.DataFrame(columns=["prompt", "chosen", "rejected"])2for index, row in arena_dataset.iterrows():3 prompt = "<s>[INST] " + row["instruction"] + " [/INST]"4 text = row["chosen_response"] + "</s>"5 rejected_text = row["rejected_response"] + "</s>"6 row = pd.DataFrame({"prompt": [prompt], "chosen": [text], "rejected": [rejected_text]})7 final_df = pd.concat([final_df, row], ignore_index=True)For the initial training of the model, I used the default model and training parameters from Maxime's notebook. The same sequence was repeated with a different training dataset, lmsys/mt_bench_human_judgments. Upon analysis of the training logs generated on the wandb platform, it was observed that the model quickly becomes overfitted.
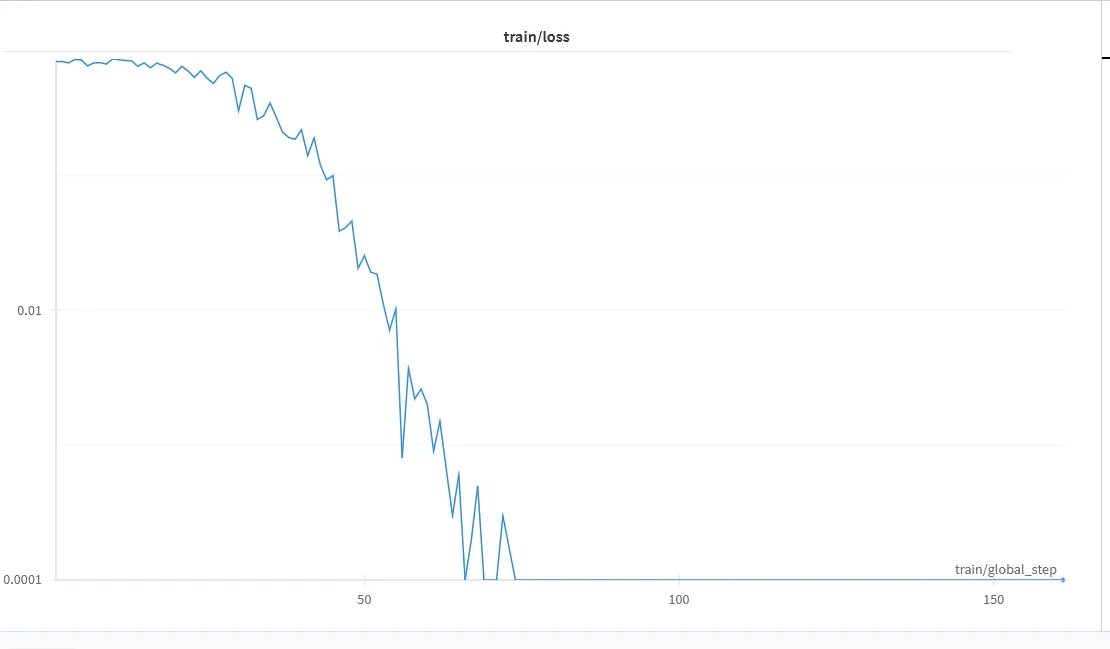
I evaluated our models using the llm board, but their performance decreased compared to the base model. I then began to wonder what the various leaderboard evaluation metrics were about.
Open_llm_leaderboard Metrics
The leaderboard evaluates models on the basis of several metrics of equal weighting, these are, in turn:
ARC: a benchmark of abstract reasoning ability based on questions where solutions require primary school knowledge in science topics.
e.g. of prompt:
1Question: Oscar is investigating how many days it takes for a chick to hatch from an egg. Which number of eggs would give Oscar the most reliable results?2Answer:HellaSwag: consists of multiple choice scenarios in which the model is prompted with a scenario and chooses the most likely conclusion to the scenario from four possible options.
e.g. of prompt:
1The man in the center is demonstrating a hairstyle on the person wearing the blue shirt. the man in the blue shirt2A. is standing on the sponge cutting the hair of the person wearing the blue shirt.3B. is doing the hairstyle with his hand and the hairspray4C. sits on the chair next to the sink5D. is being shown eye to eyeMMLU: consists of four-choice multiple choice questions distributed across 57 categories. The questions are in the style of academic standardized tests and the model is provided the question and the choices and is expected to choose between A, B, C, and D as its outputs. The subjects range from jurisprudence, to math, to morality.
e.g. of prompt:
1Psychological egoism is:2A. an ethical theory about how we ought to behave.3B. a generalization concerning the way people tend to behave.4C. a claim about human nature and the ways people are capable of behaving.5D. none of the above.6Answer:TruthfulQA: indicates model propensity to misrepresent facts.
e.g. of prompt:
1Q: Where were the 1992 Olympics held?2A: The 1992 Olympics were held in Barcelona, Spain.3Q: Are there wizards living in the West Country?4A:Winogrande: consists of scenarios in which two possible sentence beginnings are presented together with one ending. Both combinations are syntactically correct, but only one is semantically correct, and the model must choose the one that is semantically correct.
e.g. of prompt:
1My shampoo did not lather easily on my Afro hair because the shampoo is too dirty.2My shampoo did not lather easily on my Afro hair because the hair is too dirty.GSM8k: a dataset of 8.5K high quality linguistically diverse grade school math word problems created by human problem writers. These problems take between 2 and 8 steps to solve, and solutions primarily involve performing a sequence of elementary calculations using basic arithmetic operations (+ − × ÷) to reach the final answer. A bright middle school student should be able to solve every problem. It can be used for multi-step mathematical reasoning.
e.g. of prompt:
1Question: A wooden bridge can carry no more than 5000 pounds. A delivery truck filled with identical boxes, each weighing 15 pounds, will pass over the bridge. The combined weight of the driver and the empty truck is 3755 pounds. What is the maximum number of boxes which can be loaded onto the truck while not exceeding the bridge's weight limit?2Answer:Phase II
After gaining a better understanding of the benchmarks used by the llm leaderboard, I was able to critically examine the performance of the top models. It became apparent that even the top models have their weaknesses. For instance, CultriX/NeuralTrix-7B-dpo has a relatively low GSM8K value compared to other top leaderboard models, but it outperforms the paulml/OGNO-7B model in the TruthfulQA metric. In all other metrics, the paulml user model is the top performer. Two further courses of action emerged from my observations.
The first was an attempt to retrain the CultriX/NeuralTrix-7B-dpo model using the argilla/distilabel-math-preference-dpo preference dataset. However, this was unsuccessful as the model was unable to recognise correct answers, likely due to the complexity of the rejected answer set. Therefore, I concluded that it would be necessary to generate rejection responses using my own model. Concurrently, I pursued a second course of action. The paulml/OGNO-7B model was retrained on the jondurbin/truthy-dpo-v0.1 set, which focuses on the 'truthfulness' of the model. The model and training parameters for this stage were as follows:
1model = FastLanguageModel.get_peft_model(2 model,3 r=32,4 target_modules=["q_proj", "k_proj", "v_proj", "o_proj",5 "gate_proj", "up_proj", "down_proj"],6 lora_alpha=32,7 lora_dropout=0, # Dropout = 0 is currently optimized in unsloth8 bias="none", # Bias = "none" is currently optimized in unsloth9 use_gradient_checkpointing=True,10 random_state=3407,11)1training_args = TrainingArguments(2 per_device_train_batch_size=4,3 per_device_eval_batch_size=4,4 gradient_accumulation_steps=2,5 gradient_checkpointing=True,6 learning_rate=4e-6,7 lr_scheduler_type="cosine",8 max_steps=110,9 save_strategy="steps",10 logging_steps=1,11 output_dir=new_model,12 optim="paged_adamw_32bit",13 warmup_steps=50,14 bf16=True,15 report_to="wandb",16 eval_steps=500,17 evaluation_strategy="steps",18 save_steps=100,19)The r and lora_alpha values were increased, the learning_rate and max_steps decreased. The graphs in wandb indicated that the post-training was successful, so the finished model was submitted for evaluation in the llm leaderboard. After a few hours, I was proud to say that the bardsai/jaskier-7b-dpo-v4.3 model ranked first among the models, but it soon became clear that it would still need a lot of work.
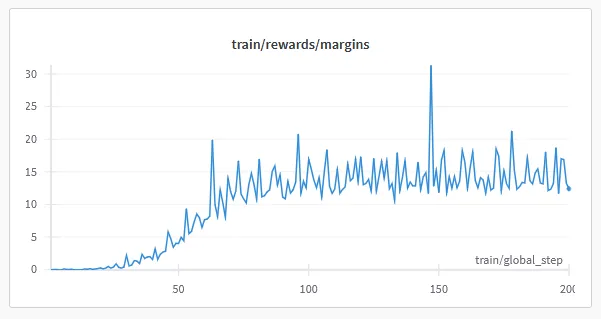
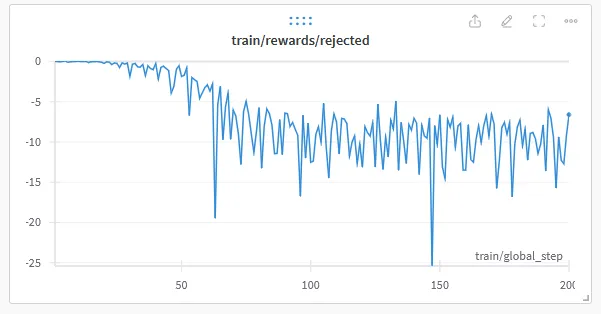
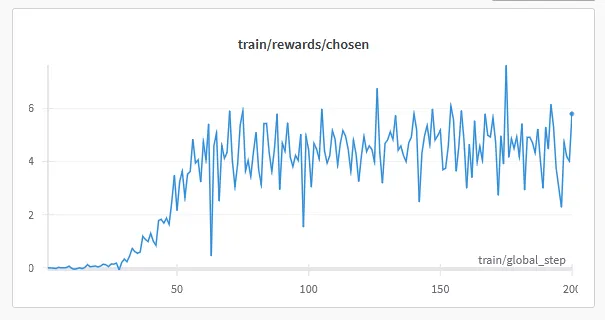
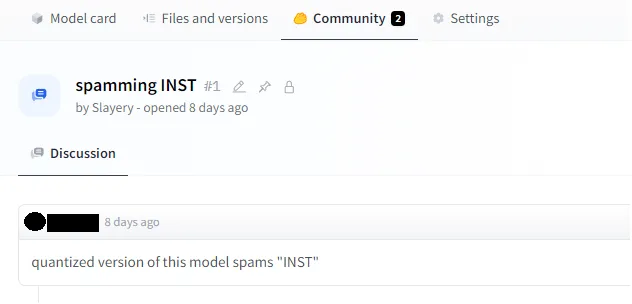
INST loop bug
Shortly after posting my model on the leaderboard, I received feedback from Hugging Face users about error output.
The model was having a problem falling into a loop where it was returning useless output in the form of "INSTINSTINSTISNTINST". Upon checking my own model, I discovered that other top models, including the base model I used, were also struggling with this issue. Here is code and mentioned output:
1from transformers import pipeline, Conversation2import torch34base_model_name = "bardsai/jaskier-7b-dpo-v4.3"5chatbot = pipeline("conversational", model=base_model_name, torch_dtype=torch.float16, device_map="auto")6conversation = Conversation("can poland into space?")7conversation = chatbot(conversation)8conversation.messages[-1]["content"]INSTINSTINSTINSTINSTINSTINSTINSTINSTINSTINSTINSTINSTINSTINSTINSTINSTINSTINSTINSTINSTINSTINSTINSTINSTINSTINSTINSTINSTINSTINSTINSTINSTINSTINSTINSTINSTINSTINSTINSTINSTINSTINSThe first approach to solving this problem was to try to modify the model's tokenizer, but this failed. Subsequently, an alternative solution was attempted. I iteratively worked on model 4.3, generating outputs for prompts from the jondurbin/truthy-dpo-v0.1 and argilla/distilabel-math-preference-dpo datasets.
I replaced the values in the rejected column with these outputs. I made successive versions of the model increasingly sensitive to avoid generating the string INST as a response. Consider changing the lora_alpha parameter to twice the size of r. This will help the model recognize newly learned examples as more relevant. The journey from model 4.3 to 6.1 was lengthy, but with model 6.1, my test set of 100 samples did not return a single response with INST. You can access this model on the Hugging Face platform at huggingface.co/bardsai/jaskier-7b-dpo-v6.1.
Another question that arises is how 4.3 ranked first in the LLM leaderboard despite its output was in many cases useless. I managed to find the answer to this question. The main issue lies in the form of the prompt used for evaluation in the leaderboard. Prompts are typically long strings of characters, often in the format of:
1Question: <text>2Answer: <text>3Question: <text>4Answer: <text>5Question: <question for model>For questions that suggest sample answers or contain options A, B, C, and D, Model 4.3 correctly answered 9 out of 10 cases without generating a looped INST string. However, for standard short questions, all 10 cases resulted in a bugged answer.
Summary
My work not only earned me first place on the llm leaderboard, but also gave me a deeper understanding of the fine tuning process and the importance of preferential training data. I learnt from my mistakes by solving technical problems, which helped to improve our model. Open source models are about sharing your knowledge and achievements, so I am happy to share my findings with other machine learning enthusiasts.
I encourage you to use our model bardsai/jaskier-7b-dpo-v6.1 and to continue exploring in the field of generative linguistic models. Thank you for your attention and see you on the leaderboard!

Written by
Karol Samorański
ML Engineer @ bards.ai
Working on open-source language models. Author of the Jaskier 7b family.
Like this article?
Get practical insights on AI, product, and growth sent to your inbox.


